Search Engine Friendly Development: Meta Tags

Part 5 of our 8-part series on developing search engine friendly website structures. This was originally written by Rand Fishkin and Moz Staff, and posted on posted Moz. Image courtesy Becky Weatherington via Flickr.
Meta tags were originally intended as a proxy for information about a website’s content. Several of the basic meta tags are listed below, along with a description of their use.
Meta Robots
The Meta Robots tag can be used to control search engine crawler activity (for all of the major engines) on a per-page level. There are several ways to use Meta Robots to control how search engines treat a page:
- index/noindex tells the engines whether the page should be crawled and kept in the engines’ index for retrieval. If you opt to use “noindex,” the page will be excluded from the index. By default, search engines assume they can index all pages, so using the “index” value is generally unnecessary.
- follow/nofollow tells the engines whether links on the page should be crawled. If you elect to employ “nofollow,” the engines will disregard the links on the page for discovery, ranking purposes, or both. By default, all pages are assumed to have the “follow” attribute.
Example: <META NAME=”ROBOTS” CONTENT=”NOINDEX, NOFOLLOW”> - noarchive is used to restrict search engines from saving a cached copy of the page. By default, the engines will maintain visible copies of all pages they have indexed, accessible to searchers through the cached link in the search results.
- nosnippet informs the engines that they should refrain from displaying a descriptive block of text next to the page’s title and URL in the search results.
- noodp/noydir are specialized tags telling the engines not to grab a descriptive snippet about a page from the Open Directory Project (DMOZ) or the Yahoo! Directory for display in the search results.
The X-Robots-Tag HTTP header directive also accomplishes these same objectives. This technique works especially well for content within non-HTML files, like images.
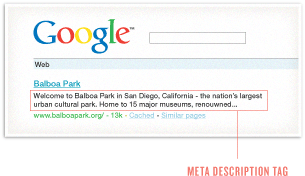
Meta Description
The meta description tag exists as a short description of a page’s content. Search engines do not use the keywords or phrases in this tag for rankings, but meta descriptions are the primary source for the snippet of text displayed beneath a listing in the results.
The meta description tag serves the function of advertising copy, drawing readers to your site from the results. It is an extremely important part of search marketing. Crafting a readable, compelling description using important keywords (notice how Google bolds the searched keywords in the description) can draw a much higher click-through rate of searchers to your page.
Meta descriptions can be any length, but search engines generally will cut snippets longer than 160 characters, so it’s generally wise to stay within in these limits.
In the absence of meta descriptions, search engines will create the search snippet from other elements of the page. For pages that target multiple keywords and topics, this is a perfectly valid tactic.
Not as important meta tags
Meta Keywords: The meta keywords tag had value at one time, but is no longer valuable or important to search engine optimization. For more on the history and a full account of why meta keywords has fallen into disuse, read Meta Keywords Tag 101 from SearchEngineLand.
Meta Refresh, Meta Revisit-after, Meta Content-type, and others: Although these tags can have uses for search engine optimization, they are less critical to the process, and so we’ll leave it to Google’s Webmaster Tools Help to discuss in greater detail.
Leave a Reply
Want to join the discussion?Feel free to contribute!